





Hur tillämpar du industridata till din produktion?
Det kan tyckas att de flesta tillverkningsföretag drunknar i industridata, men strävar fortfarande efter att dra nytta av de möjligheter detta ger. Vi ger dig en praktisk guide i sju steg.
En modern industrianläggning kan producera en terrabyte av industridata varje dag. Med en våg av ny teknik inom artificiell intelligens och maskininlärning samt instrumentpaneler med realtidsdata står vi inför stora möjligheter för optimerad produktion. Oplanerat underhåll av produktionsutrustning borde vara ett minne blott.
Ändå är detta inte fallet år 2021. Tillgång till stora mängder industridata är inte synonymt med att användas för något användbart. Industriella data kommer obehandlade och måste bearbetas innan det verkliga värdet kan extraheras. Verktygen som används för detta måste också kunna hantera en expansion av fabriksanläggningen.
Så hur gör man industriella data lämpliga för din användning? Med de nämnda utmaningarna i åtanke presenterar vi en steg-för-steg-guide.
Steg 1: Starta med use case
Projektet startar med att definiera ett tydligt use case. Det kan vara maskinunderhåll, processförbättringar, produktionsuppföljning, förbättrad kvalitet eller uppföljning av spårbarhet. Som en del av use caset måste företagets olika beslutsfattare identifiera projektets omfattning. Det är viktigt att olika roller är involverade för att gemensamt komma överens om projektets gemensamma mål.
Steg 2: Identifiera mottagaren av den strukturerade data
När ni har identifierat era affärsmål och use case måste ni bestämma vilka system som behövs för att uppnå dessa mål. Ställ er dessa frågor:
- Var finns denna målapplikation: at the Edge, lokalt, i ett datacenter, i molnet, etc.?
- Hur kan denna applikation ta emot data: MQTT, OPC UA, REST, etc.?
- Vilken information behövs?
- Hur ofta ska data uppdateras och varför?
Dokumentera dina svar och gå sedan vidare till nästa steg där du kommer att identifiera dina datakällor för projektet.
Steg 3: Identifiera datakällorna
Industridata är en viktig komponent för att hantera användningsfallet. Att skaffa industridata och omvandla den till användbar information kan vara utmanande. Därför är det viktigt att ha en överblick över tillgänglig data.
Volym
En typisk, modern industrianläggning har hundratals till tusentals maskindelar och utrustning som kontinuerligt producerar data via PLC, maskinkontroller eller distribuerat styrsystem (DCS). Nyare automationssystem kan också innehålla smarta sensorer och smarta ställdon.
Korrelation
Automationsdata är främst för att hantera, optimera och styra processen. Dessa uppgifter är relaterade till processkontroll och gäller inte underhåll, produktkvalitet eller spårbarhet.
Kontext
Datastrukturen från PLC och kontroller har minimal beskrivande information. Datapunkterna hänvisas ofta till med kryptisk namngivning eller till adressplatsen i minnet.
Standardisering
Automatiseringen i en fabrik utvecklas över tid med maskiner och utrustning från olika leverantörer av hårdvara. Detta är hårdvara som förmodligen är programmerad och definierad av leverantören. Som ett resultat ser man unika datormodeller gjorda för varje enskild maskin, med avsaknad av en gemensam standard för fabrik och organisation.
För att förstå de specifika utmaningarna bör datakällorna dokumenteras. Sedan kan du ställa följande frågor för att beskriva vilken tillgänglig data du behöver för att uppnå projektmålen:
- Vilken industridata finns tillgängliga?
- Var finns data: PLC, kontroller, databas eller någon annanstans?
- Är det realtidsdata eller metadata?
- Är data tillgängliga i rätt format, eller behövs det databehandling?
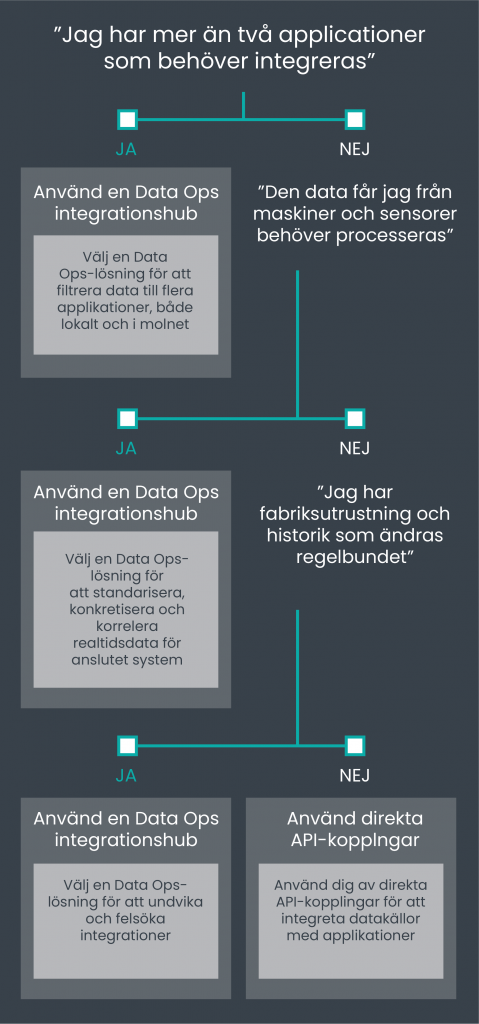
Steg 4: Välj integrationsarkitektur
Integrationsarkitektur är antingen direkta API-anslutningar (applikation-till-applikation) eller integrationshubbar (DataOps-lösningar).
Anslutning till API fungerar bra om bara två applikationer ska integreras. Data behöver inte behandlas för den mottagande applikationen och källsystemen är statiska. Detta fungerar bäst där endast en SCADA- eller MES -lösning har all information, och det finns inga andra applikationer som behöver tillgång till data.
Direkta API -länkar fungerar dåligt när det finns behov av att hämta industridata via olika applikationer, till exempel SCADA, MES, ERP, IIot Platform, Analytics, QMS, AMS, säkerhetssystem, olika databaser, instrumentpaneler eller kalkylprogram. Detsamma gäller om det sker många datatransformationer före överföring. Dessa transformationer kan enkelt göras i Python, C # eller andra programmeringsspråk, men det betyder att transformationerna blir “osynliga” och svåra att underhålla. API -länkar står också inför utmaningar om datastrukturen ändras regelbundet. Detta kan hända när fabriksutrustning byts ut eller ändringar görs i programmet som kör utrustningen. Vanliga skäl för att byta utrustning eller program kan vara:
- Tillverkaren har små satser, vilket kräver att du måste ladda nya program på PLC:erna.
- Produkterna ändras och kräver därför en ändring av automatiseringen.
- Automatisering förändras för att öka produktiviteten.
- Utrustning byts ut på grund av ålder och prestanda.
Genom att använda API döljer integrationen i koden. Intressenter kan vara omedvetna om att ändringar görs i integrationen, vilket kan leda till att fel eller saknade data inte upptäcks förrän efter flera veckor eller månader.
Ett alternativ till direkta API-kopplingar är DataOps Integration Hub. DataOps är ett nytt tillvägagångssätt för dataintegration och säkerhet, som syftar till att förbättra datakvaliteten och minska den tid det tar att behandla data före användning i organisationen. En integrationshub fungerar som ett abstraktionslager som ger alla applikationer tillgång till administrations-, dokumentations- och hanteringsverktyg.
Integrationsnavet är speciellt byggt för att flytta stora mängder data med hög hastighet, med transformationer utförda i realtid medan data är i rörelse. Som en applikation fungerar DataOps Integration Hub som en plattform för att identifiera effekterna av förändringsutrustning och andra applikationer, samt utföra synliga datatransformationer.
Steg 5: Skapa säkra kopplingar
Med projektplanen på plats börjar systemintegrationen med att skapa säkra källor och målsystem. Det är viktigt att förstå vilka protokoll som jobbar på och vilka säkerhetsrisker och fördelar de ger.
Många system stöder öppna protokoll för att definiera kontaktpunkter och kommunikation. Typiska öppna protokoll inkluderar OPC UA, MQTT, REST, ODBC och AMQP. Det finns också många slutna protokoll och API -system som definieras av applikationsleverantören. Ställ följande frågor:
Stödjer protokollet säkra anslutningar, och hur upprättas dessa anslutningar?
Vissa protokoll och system stöder certifikat som utbyts mellan applikationer. Andra protokoll stöder användarnamn och lösenord eller tokens som matas in manuellt i anslutningssystemet eller genom en tredjepartsvalidering. Förutom användarsäkerhet stöder vissa protokoll krypterade datapaket, som förhindrar att data läses i en insiderattack. Slutligen finns det protokoll som stöder datautentisering. Det betyder att även om uppgifterna visades av en tredje part kommer det inte att vara möjligt att ändra den.
Säkerhet handlar inte bara om användarnamn, lösenord, kryptering och autentisering, utan också om integrationsarkitektur. Protokoll som MQTT kräver endast utgående öppningar i brandväggar och hindrar hackare från att komma åt interna nätverk. Denna typ av protokoll föredras av säkerhetstjänstemän.
Steg 6: Modelldata
Distributionen av analys eller IloT försenas ofta av variationen i data som kommer från fabriken. Maskinleverantörer, systemintegratörer och tillverkare har inte fokuserat på att skapa datastandarder, utan snarare utveckla system över tid och anpassa sig därefter. Som ett resultat kan varje maskin ha olika datormodeller. Detta tillvägagångssätt har fungerat för engångsprojekt, men nuvarande IloT-projekt kräver mer skalbarhet.
Steg 7: Dataflöde
När modelleringen är klar bör dataströmmarna kontrolleras modell för modell. Detta görs vanligtvis genom att identifiera modellen, målsystemet och frekvensen eller utlösaren för rörelsen. Med tiden kommer dataöverföringar att kräva övervakning och kontroll.
Sammanfattning
Fabriker och andra industrimiljöer förändras med tiden. Utrustning byts ut, program ändras, produkter designas om, system uppgraderas och nya användare behöver ny information för att göra sitt jobb. Mitt i denna förändring kommer OT- och IT -proffs att samarbeta om nya projekt som syftar till att förbättra produktivitet, effektivitet och säkerhet. Det kommer att krävas Industriella data som är standardiserad och kontextualiserad. Ett verktyg behövs för att utföra denna uppgift i stor skala – som en DataOps -lösning. Genom att använda en integrationshub kan man samla in data från olika utrustningar på ett ställe, sedan standardisera och kontextualisera.
Det första steget i modellering av data är att definiera standardmodeller i målsystemet för att uppfylla projektets affärsmål. Kärnan i modellen är realtidsdata från maskiner och automationsutrustning. De flesta datapunkter i realtid kommer från en enda datakälla. När en specifik datapunkt inte finns kan andra datapunkter användas med logik. Data kan också analyseras eller hämtas från andra datafält. Eventuellt kan ytterligare sensorer läggas till för att tillhandahålla nödvändig data.
Dessa modeller bör innehålla attribut för beskrivande data, som vanligtvis inte lagras i industriella enheter, men är användbara vid matchning och utvärdering av data i målsystem. Beskrivande data kan vara plats, serienummer, måttenhet, operatörsområde eller annan kontextuell information. När standardmodellerna väl har gjorts bör de vara avsedda för varje maskin, process eller industriell utrustning. Detta är vanligtvis en manuell uppgift, men kan påskyndas om det finns konsistens från enhet till enhet och kartläggningen redan finns i Excel eller ett annat format, eller om en inlärningsalgoritm kan användas.







